Redis 集群搭建之集群cluster模式
Redis Cluster 模式的原理介绍
如果说哨兵模式(Sentinel)像是 “带保镖的单核中心”,那么集群模式(Cluster)就是 “多中心的联邦共同体”。在 Redis Cluster 中,不再有中心化的哨兵,而是通过 去中心化 的方式实现了真正的横向扩展。
核心原理——哈希槽
Redis Cluster 没有使用简单的一致性哈希,而是引入了 哈希槽(Hash Slot)的概念。
- 槽位分配:Redis 集群固定拥有 16384 个哈希槽。
- 算法:当存入一个 Key 时,Redis 会计算 CRC16(key) % 16384,得到的结果决定了这个 Key 落在哪个槽位。
- 分片存储:集群中的每个主节点(Master)负责一部分槽位。例如:
- Node A 负责 0 - 5460 槽位
- Node B 负责 5461 - 10922 槽位
- Node C 负责 10923 - 16383 槽位
为什么是hash槽而不是一致性hash?
一致性哈希的核心是一个 $2^{32}$ 的虚拟圆环。节点分散在环上,Key 通过哈希计算后顺时针寻找最近的节点。最明显的优点是极致的平滑扩容,增加或删除一个节点时,只影响环上相邻的一小部分数据,不会导致全量数据的重新分布。缺点也非常明显,容易导致数据倾斜,如果节点较少,数据分布极不均匀(虽然可以通过引入大量“虚拟节点”解决,但增加了管理复杂度);并且客户端很难精准知道当前数据在哪,通常需要通过中间代理。
而hash槽则完成了 “数据” 与 “节点” 的解耦:数据绑定在槽(Slot)上,而槽绑定在节点上。你可以手动指定 Node A 负责 5000 个槽,Node B 负责 1000 个槽。在扩容时,你可以根据机器性能精准地迁移某几个槽。路由也很透明简单,客户端只需要缓存一份 slot -> node 的映射表即可。唯一的缺点是扩容开销稍大:扩容时需要手动(或调用命令)进行槽位迁移,迁移过程中涉及数据的物理搬迁。
Redis 选择hash槽的设计,是基于一下三个最核心的原因:
- 数据与节点的解耦:一致性哈希中,节点在环上的位置是计算出来的,数据直接与节点绑定,不容易管理和控制;哈希槽的设计解耦了数据与存储节点,数据存放在哪个节点上完全是槽位分配的结果,Redis 作为一个高性能数据库,需要绝对精确地定位数据,哈希槽让 “哪块数据在哪台机器” 变得清晰可控。
- 重新分片(Resharding)的便利性:一致性哈希只能在相邻节点间腾挪数据,很难做到 “我从 A 挪一点给 C,再从 B 挪一点给 C” 这种跨节点的精细化调整。Hash槽就像一个个抽屉。我想把 100 号抽屉给谁就给谁。Redis Cluster 提供的 “cluster setslot” 命令配合数据迁移,能让运维非常方便地平衡集群负载。
- 解耦带来的容错性:如果一致性哈希环上的某个节点挂了,它的压力会全部涌向顺时针的下一个节点,可能导致雪崩。 而在哈希槽架构中,如果一个节点挂了,它的从节点(Slave)会接管它负责的所有槽位,槽位分布保持不变,不会对其他主节点产生连锁反应。
Redis 的设计哲学是 “简单且可控”。 一致性哈希在分布式缓存(不需要持久化、丢点数据没关系)中表现极佳;但对于 Redis 这种 有状态的数据库,数据的完整性和迁移的确定性更重要。哈希槽虽然看起来多了一层映射,但它赋予了运维人员对数据的 绝对掌控权。
集群模式主要解决的问题
相比哨兵模式,集群模式是为 “大规模、高吞吐” 而生的:
- 海量数据存储:哨兵模式受限于单机内存。集群可以将数据分布在多台机器上,理论上可以存储几十 TB 的数据。
- 写负载均衡:哨兵模式下只有主库能写。集群模式下有多个主节点,所有主节点都可以承担写压力。
- 去中心化故障转移:不再依赖哨兵进程。节点之间通过 Gossip 协议 互相通信(心跳检测),一旦发现某个主节点挂了,其余主节点会投票选举出它的从节点上位。
集群模式的主要应用场景
- 超大规模缓存/数据库:当你的数据量超过 64GB(单机建议上限)时。
- 高并发写需求:例如直播间弹幕、秒杀抢购、大规模物联网设备状态采集等。
- 弹性扩容需求:业务增长很快,需要随时能在线加机器(集群支持动态迁移槽位)。
实际的建议:如果你目前的业务量在 10GB 级以内,且读多写少,保持现有的 哨兵读写分离 即可,它是最稳定、运维成本最低的选择。如果未来你的用户量涨了 数十倍,再考虑重构成集群。
实践中的深度避坑
虽然集群很强,但在高性能要求的系统中,如果不注意以下坑,集群会比单机更慢:
多键操作的限制:Redis Cluster 要求同一个事务或 “MGET/MSET” 中的所有 Key 必须在同一个槽位。比如你执行 “mget {key1} {key2}”,而这两个 Key 分布在不同的节点上,程序会报错。可以适当使用 Hash Tag。例如 “set {user100}:profile” 和 “set {user100}:order”。大括号里的内容决定槽位,这样就能保证它们落在同一个节点。热点 Key (Hot Key) 问题:由于数据是按槽分片的,如果某个 Key(如大 V 的直播间)被瞬间高频访问,压力还是会全部集中在某一个节点上,集群的横向扩展能力此时无效。此时可以采用本地缓存(如 Caffeine)或 Key 加上随机后缀(如 key_1, key_2)来解决这一问题。网络抖动触发 “集群脑裂”:由于集群节点间通过 Gossip 协议通信,如果网络抖动,节点间以为对方挂了,可能会频繁触发故障切换(Failover)。如果出现这种情况 ,应当适当调大cluster-node-timeout(默认 15s),防止在网络拥塞时发生误判。总线端口:确保防火墙放行17001和17002(原生端口 + 10000)。这是节点间通过 Gossip 协议交流的通道,不通则无法感知成员变化。客户端重定向 (MOVED / ASK):如果你用的客户端不够聪明(不支持集群路由),它可能会随机连到一个节点,然后被回复一个 MOVED 错误,告诉它去另一个 IP 找数据。这会增加一次网络往返(RTT)。实际的生产环境必须使用支持 Cluster 模式的客户端(如 Lettuce),它会本地缓存一份槽位映射表。
搭建redis cluster集群
主机准备
在测试环境下,我们将 6 个实例交叉部署在 3 台机器上。这样即使其中任何一台物理服务器彻底宕机,集群依然能保持运行。
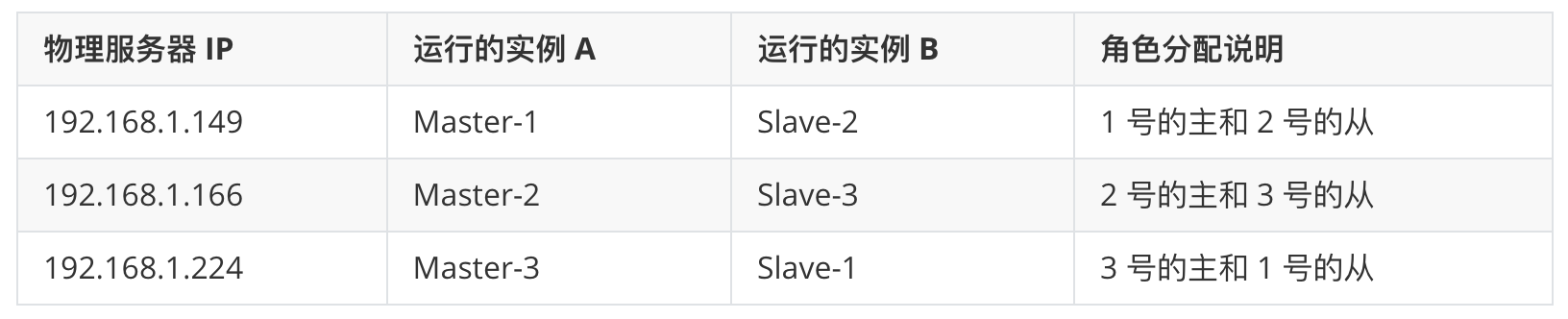
主机环境准备
1 | # 【极其重要】集群节点时间同步! |
配置文件准备和下发
编写配置文件模板(如果想要保留更多原始的配置信息,可以在原有官方配置文件的基础上只更改下述参数):
1 | $ vim /etc/redis/cluster/redis_template.conf |
我们在每台机器上部署两个实例,端口分别为 7001 和 7002,在每个主机上准备好配置文件和相关目录:
1 | # 使用 sed 批量替换 "${PORT}" 变量,生成配置文件,并下发到每台服务器 |
启动实例
在三台机器上分别启动两个 Redis 进程:
1 | # 启动 7001 |
验证启动状态:
1 | ps -ef | grep redis-server |
创建集群 (核心步骤)
这一步只需在 192.168.1.149 这一台机器上执行。我们将使用 --cluster-replicas 1 参数,它会自动为每个 Master 分配一个 Slave。
1 | redis-cli -a 123456 --cluster create \ |
注意:redis-cli 会自动尝试计算最佳的错位布局(比如把 149:7001 的从节点放在 166 或 224 上)。
企业级测试验证
检查集群状态
1 | redis-cli -a 123456 -c -h 192.168.1.149 -p 7001 cluster info |
- 确保 cluster_state:ok
- 确保 cluster_slots_assigned:16384
1 | redis-cli -a 123456 -p 7001 info cluster |
- 如果显示:cluster_enabled:1 则表示配置正确,可以继续执行创建命令。
1 | redis-cli -a 123456 -p 7001 cluster nodes |
验证数据分片与自动重定向 (-c 参数)
1 | # 使用 -c 开启集群模式连接 |
故障模拟测试 (最重要)
1 | # 在 192.168.1.149 上杀掉 7001 进程: |
- 原本 149:7001 的状态应变为 fail
- 它对应的从节点(166:7002)应该自动切换为 master。
如何将节点重新加入集群
场景一:配置文件和数据还在(最简单)
如果你只是 kill 了进程,没有删除例如 /usr/local/redis-cluster/7001/data 目录下的 nodes-7001.conf 文件,那么操作非常简单,直接启动实例即可。原理是 Redis 启动时会读取 nodes-7001.conf。它会发现自己曾经属于某个集群,并尝试联系集群中的其他成员。只要它联系上了任何一个健康的节点,它就会自动同步状态并重新加入集群。
1 | # 直接启动该实例 |
你会看到 149:7001 的状态从 fail 慢慢变成 slave(如果它的 Master 此时已经由别的节点担任)或者恢复为 master。
场景二:如果启动后它没有自动加入(或显示没有槽位)
如果因为网络或其他原因,启动后它变成了一个“孤独的节点”,或者你清理过数据目录,你需要手动将其引导回集群。
1 | # 握手(Meet) 在 149:7001 上执行,让它认识集群里的一个“熟人”(比如 166:7001) |
场景三:企业级运维的 “终极归队法”
如果你的节点数据彻底乱了,或者你想以“新节点”身份加入,标准的做法是使用 redis-cli –cluster 工具:
1 | # 停止 7001 |
如何手动指派master

如图,我们发现 166 这台机器上有两个master节点,这种集群是很不健康的,在当前的集群状态下,一旦166这台机器挂了,我们至少会丢失 2/3 的数据!那么如何修正让集群回归 “健康” 的均衡状态呢?
方案 A:手动强制切换(最推荐,最受控)
如果你想让 149 重新拿回一个 Master 身份,你可以去 149 上执行“夺权”指令。
1 | # 登录到 192.168.1.149:7001(它现在是 slave) |
效果是 149:7001 会通过与 166:7002(它的主)协商,安全地接管槽位,自己变回 Master,把 166 的那个实例降级为 Slave。

方案 B:使用集群工具自动均衡
如果你不介意槽位微调,可以执行:
1 | redis-cli -a 123456 --cluster rebalance 192.168.1.149:7001 --cluster-use-empty-masters |
集群模式常用指令
节点管理指令
这类指令主要用于调整集群拓扑结构。
1 | # 最常用。列出所有节点 ID、角色、主从关系、槽位分配及连接状态。 |
槽位与数据指令
这是 Redis Cluster 处理数据的核心,主要用于在线扩容和缩容。
1 | # 以数组形式返回槽位分布,比 nodes 更适合程序解析。 |
我怎么知道某个 Key 到底在哪台机器上?
- 先执行 cluster keyslot mykey 得到槽位(假设是 12580)。
- 查看 cluster nodes,寻找负责 12580 的 Master IP。
- 或者直接用 “redis-cli -c” 登录,它会自动帮你跳转。
命令行工具 (运维利器)
官方提供的 “傻瓜化” 运维工具(redis-cli –cluster),比进入交互式窗口写指令更高效。
① 集群检查与修复
1 | # 检查集群是否健康,槽位是否完整 |
② 动态扩容与缩容
1 | # 添加主节点 |
重置指令
1 | # SOFT:仅清理节点元数据,保留数据。 |
Readonly 指令
readonly 和 readwrite 两个指令是专门为从节点(Replica)设计的指令。在 Redis Cluster 默认情况下,所有的读写请求都必须由 Master 节点处理。即使你直接连接到了从节点的 IP,如果你尝试执行 GET,它也会给你返回一个 MOVED 错误,强迫你跳转回主节点。
- READONLY:作用是开启从节点阅读权限,它告诉从节点:“我作为一个客户端,已经知道我连接的是从库,并且我接受可能存在的微小主从同步延迟,请允许我在当前连接上执行读操作”。它只对当前这个客户端连接有效。如果新开一个窗口,需要重新发送 READONLY。使用 READONLY 依然禁止写入,即使执行了 READONLY,如果你尝试 SET,它依然会把你踢回 Master。
- READWRITE:作用是恢复默认行为,即撤销 READONLY 指令的效果,将当前连接恢复到默认状态(即所有请求重定向回 Master)。
1 | > readonly |
之所以这样设计,是因为Redis Cluster 追求的是 强一致性路由。如果允许客户端随意读取从节点,可能会读到尚未同步完成的脏数据。Redis 强制 MOVED 重定向是为了确保你永远访问的是 “权威数据源”(Master)。只有当你显式发送 READONLY 时,才代表你知情并同意承担读到过期数据的风险。在实际开发中,你几乎不需要手动在代码里写 READONLY,因为现代驱动(如 Lettuce)已经帮你封装好了。如果你在 Spring Boot 中配置了 LettuceClientConfiguration 的 ReadFrom(REPLICA_PREFERRED),Lettuce 会在后台自动管理连接,当它连接从库准备读数据时,它会自动先发一个 READONLY,这一切对你的业务代码是透明的。
当你使用 redis-cli 登录从节点进行数据排查时,发现 “keys *” 什么都搜不到(可能因为重定向了),这时候直接敲一下 READONLY,数据就全出来了。